Data Visualization
Data Visualization is a broad field influenced in different ways by scientists, journalists, designers and many more. Whilst the intentions of those producing data graphics varies, data visualization is seen as increasingly necessary to modern data analysis — where visual approaches are used to explore structure in large, often repurposed datasets and to communicate that structure and associated uncertainty information.
Tools for creating data visualizations vary from low-level programming environments that offer immense flexibility (e.g. Processing) to higher level frameworks aimed to support rapid generation of (re-configurable) graphics (e.g. ggplot2, Vega-Lite).
There is a large literature defining visualization and providing guidelines on good visualization design (a set of primers appears in the reference list). However, effective data graphics typically have the following characteristics:
-
Represent data dimensions, connections and comparisons that could not be achieved using non-visual means.
-
Are data rich: present many numbers in a small space.
-
Reveal patterns at several levels of detail: from broad overview to fine structure.
-
De-emphasise non-data items and omit redundant information.
Considering these characteristics, take a look at the data graphics below, which present results data from the 2016 US Presidential Election. Use the links to read the full stories (and data analyses) that accompany the graphics.
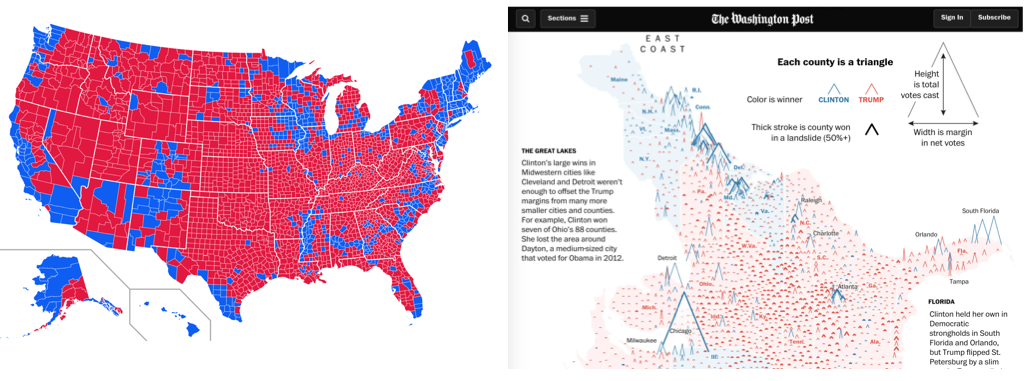
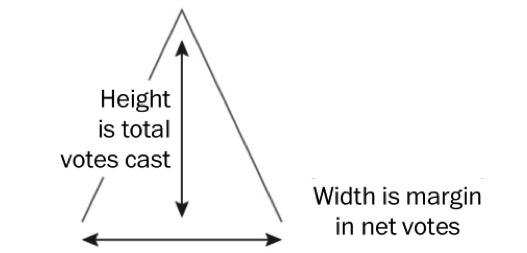
Both maps use 2016 county-level results data, but the The Washington Post graphic graphic encodes many more data items than the Medium post (see table below).
It is not simply the data density that makes the Washington Post graphic successful. The authors carefully incorporated annotations and transformations in order to support comparison and emphasise structure. By varying the height of triangles according to the number of votes cast, the thickness according to whether or not the result for Trump/Clinton was a landslide and rotating the scrollable map 90 degrees, the very obvious differences between metropolitan, densely populated coastal counties that voted emphatically for Clinton and the vast number of suburban, provincial town and rural counties (everywhere else) that voted Trump, were exposed.
| Data item | Washington Post | Medium |
|---|---|---|
County location |
||
County result |
||
State result |
||
County votes cast (~pop size) |
||
County result margin |
||
County result landslide |
Describing, evaluating and creating data graphics
Data graphics visually display measured quantities by means of the combined use of points, lines, a coordinate system, numbers, symbols, words, shading, and color.
1983
In the Washinton Post piece, we saw a judicious mapping of data to visuals, underpinned by a careful understanding of analysis context. Information Visualization — an academic discipline devoted to the study of data graphics — provides a language for describing this process as well as empirically-informed guidelines to support design choices.
Description and evaluation
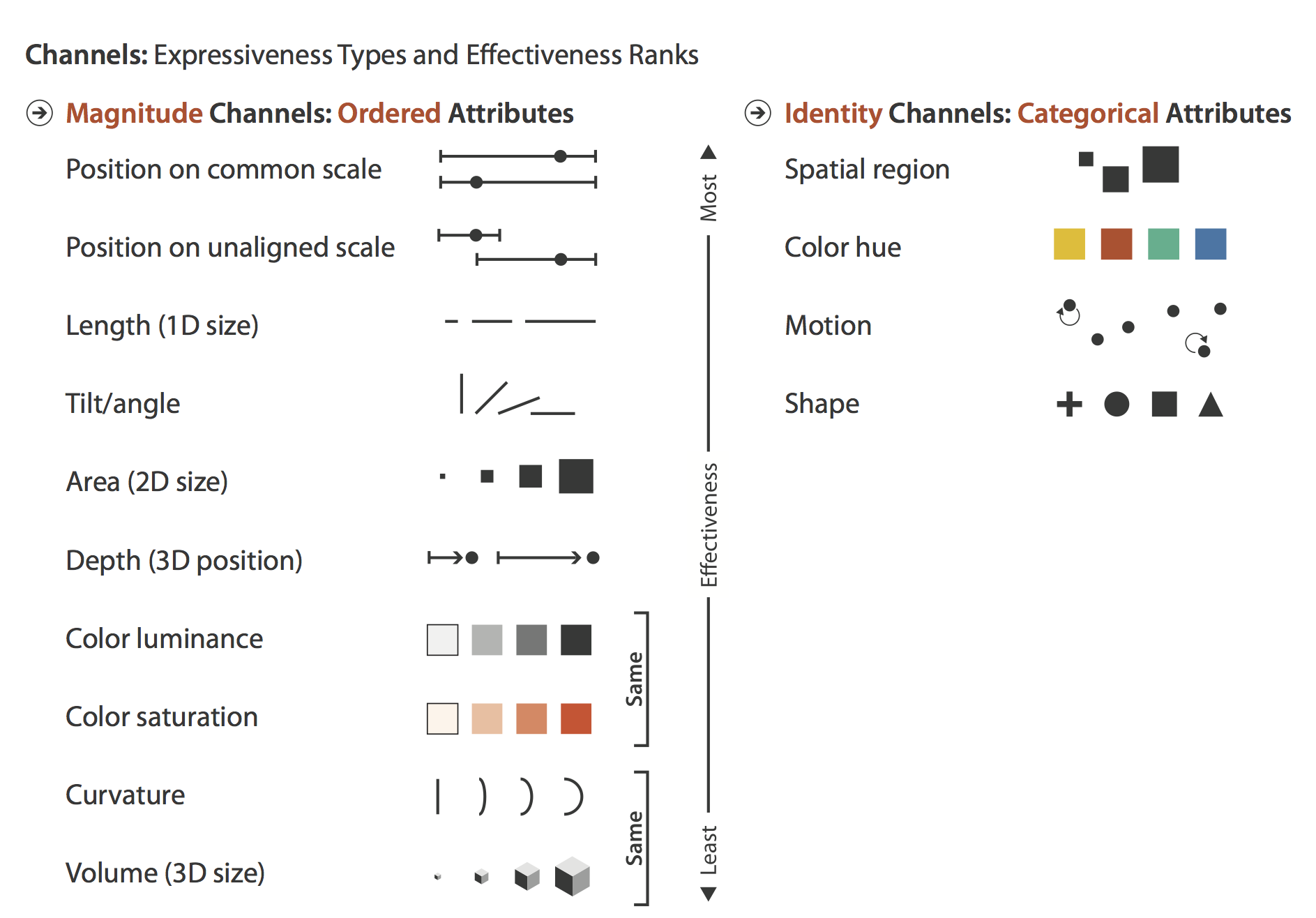
In her influential book Visualization Analysis and Design, Tamara Munzner enumerates commonly used visual marks — geometric primitives such as points, lines and areas — and visual channels that determine how marks appear (presented in Figure 2).
When creating data graphics, we specify a mapping of data items to visual channels. Some visual channels are more appropriate at showing certain data types than others. Munzner (2014) differentiates channels that are appropriate for representing categorical attributes from those appropriate for ordered and quantitative attributes. Munzner ranks these visual channels according to their effectiveness. We’ll skip the details for now, but this is an empirically-derived ordering based on decades of perception-based research in Information Visualization (Cleveland & McGill 1984 ; Heer & Bostock 2010) — we are confident it is correct.
Description and evaluation: example of the scatterplot
As an example of how we might map data attributes to visual channels in a graphic, let’s consider a familiar example of a scatterplot constructed to analyse the 2016 US election dataset.
When presenting data in a scatterplot, we usually mark observations using points. These points are typically mapped to at least one visual channel: position on the x-axis (the proportion of people in a US county with degrees) and on the y-axis (the proportion of voters in a US county supporting Trump). If we so wished, it would also be possible to vary the area of points according to something meaningful — for example, a county’s population size (Figure 3a).
The attributes so far describe quantities. If an attribute existed that described US counties in some other way (whether a county was rural, provincial town or big city), those categories could be distinguished by perhaps faceting the scatterplot to create separate versions of the plots for each category of county (Figure 3b). Considering Munzner’s (2014) ordering, we may wish to use containment within spatial region (look back to Figure 2) as a visual channel. For Munzner, spatial region describes the arrangement of small multiples in a display — this arrangement is not necessarily a geo-spatial one. However, US states are also a useful category to facet on and can clearly be arranged using containment. If we are to facet to form individual scatterplots for each state, it makes sense to arrange the small multiples according to their approximate spatial position rather than some arbitrary ordering (Figure 3b).
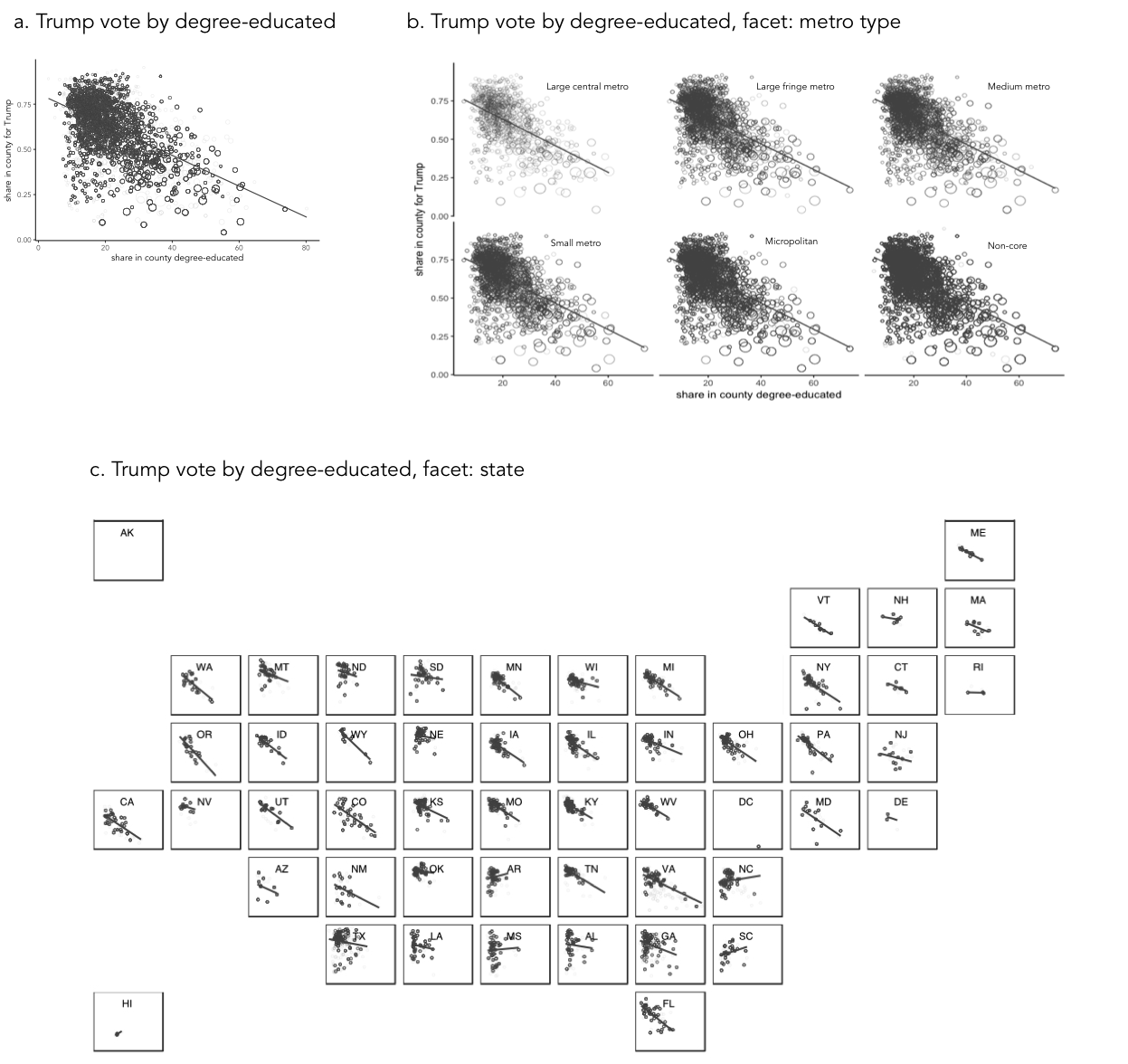
Notice that in this example of mappings, I am paying attention to the types of attributes that I wish to encode, importance to my analysis and the effectiveness of visual channels at representing those attributes. The main purpose is to explore the possible association between levels of education in a county and that county’s preference for Trump. I am using position on a common scale — the most effective visual channel — for encoding these quantities. The focus on county size (number of votes) is a secondary one, so I relegate this quantity to the area channel. And the county-type (urban-rural) is a categorical attribute and so I map this to the spatial region channel. As political/administrative entities, states are categorically distinct; however, they can be ordered according to their spatial position and so the careful use of ordering within spatial region in Figure 3c.
|
Arrangement or layout into spatial region is an important property to consider when designing data graphics. In Figure 3a and 3b, a scatterplot is faceted to form small multiples — a series of charts that share the same scale and axes and arranged for easy comparison. Notice that when faceted on state, the scatterplots are arranged according to their approximate geographic position. There is a large literature on how to effect semi-geographic arrangements. Meulemans et al. (2017) provides an overview and suggests an interesting and elegant approach. |
Description and creation: the grammar of graphics
Describing graphics in abstract terms, as with the scatterplots above and previously the Washington Post map, is useful not only for comparison of designs. Such abstract descriptions force careful consideration of the data and visual channels available and the comparisons that mappings should support: they encourage good design.
In the late 1990s, the Computer Scientist and Statistician Leland Wilkinson introduced the Grammar of Graphics — a framework for coherently and consistently describing data graphics. Wilkinson’s grammar separates a chart into a series of layers: data (clearly), transformations on that data (filters, various aggregations and binning procedures), visual marks used to represent data, a scaling that is applied when mapping data to marks (e.g. linear, log or square root) and a coordinate system (e.g. Cartesian, Polar, map projection). Once expressed in these terms, visualization design is a case of combining layers in different ways, but under a helpfully narrow vocabulary.
The Grammar of Graphics has been extremely influential in the design of high-level frameworks and technologies for visual data analysis. Tableau is underpinned by the Grammmar of Graphics; ggplot2 is a very direct implementation of Wilkinson’s theory and Vega-Lite combines a similar implementation to ggplot2, but is native to the web and, as of version 2.0, with a grammar of interaction.

Further reading
-
Munzner, T. (2014) Visualization Analysis & Design, CRC Press. Tamara Munzner, Professor of Information Visualization at University of British Columbia, provides a systematic and empirically-grounded framework for thinking about visualization. Available as an e-book via the University of Leeds Library. Chapters 2 and 5 are worth special consideration.
-
Wickham, H. (2016) ggplot2: Elegant Graphics for Data Analysis 2nd Ed. Springer.
References
-
Cleveland, W. & McGill, R. (1984) Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods. Journal of the American Statistical Association, 79(387): 532—554.
-
Heer, J. & Bostock, M. (2010) Crowdsourcing graphical perception: Using Mechanical Turk to assess visualization design, Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 203—212.
-
Munzner, T. (2014) Visualization Analysis & Design, CRC Press.
Miscellany
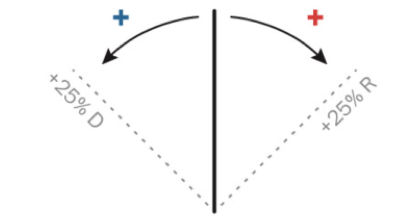
Two marks were used (lines and triangles) |
|
Colour hue (a categorical channel) was mapped to a categorical attribute |
|
Orientation (a quantitative channel) was mapped to a quantitative attribute (change in margin size) |
|
Length (a quantitative channel) was mapped to quantitative attributes (number votes, size of margin) |
|


Content by Roger Beecham | 2018 | Licensed under Creative Commons BY 4.0.